
Robust Speech Recognition via Large-Scale Weak Supervision (Whisper / OpenAI)
當然啦,在開源的世界裡不可能只有一個,完全不意外的馬上就有很多相關的開源繼續冒出
Whisper對於中文語音辨識與轉寫中文文字最佳化的實踐 而這篇可以先瞄一下,因為講到了 whisper 雖然可以透過 prompt 來做標點符號 (為什麼?因為跟後面的糾錯可能有關),但是效果仍有待強化,所以得用另外的模型來輔助 ! (2024/08 補充新增:使用🤗 Transformers 為多語種語音辨識任務微調Whisper 模型、使用Hugging Face 推理終端機建立強大的「語音辨識+ 說話者分割+ 投機解碼」工作流程、使用推測解碼使Whisper 實現2 倍的推理加速)
https://github.com/huggingface/speech-to-speech
ASR 大模型訓練方案來啦!
- https://github.com/guillaumekln/faster-whisper
- https://github.com/m-bain/whisperX
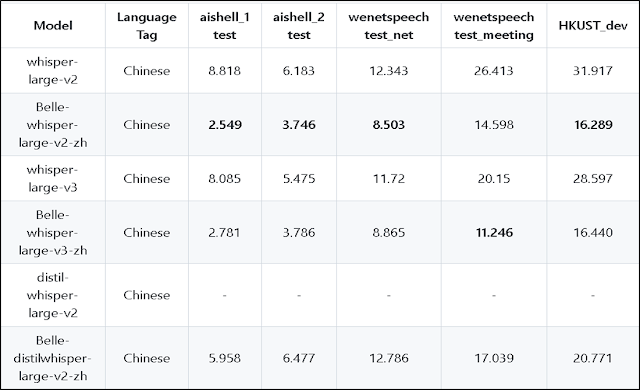
- https://huggingface.co/BELLE-2
- https://github.com/shuaijiang/Whisper-Finetune
- https://Systran/faster-whisper-large-v3
- https://github.com/huggingface/peft
- https://github.com/ufal/whisper_streaming
- https://github.com/Vaibhavs10/insanely-fast-whisper
- https://github.com/ggerganov/whisper.cpp
- https://github.com/Const-me/Whisper
- https://github.com/collabora/WhisperSpeech
- https://github.com/collabora/WhisperLive
- https://github.com/collabora/WhisperFusion
首先是 2 whisperX,主要是曾經有過需要幫ASR產生的文稿加上時間戳記,所以就這樣找到了它,看資料 2 是由 1 faster-whisper 所優化而來的;3 BELLE-2 則應該是以LLM為主,但他也開源了幾個微調過的 whisper,目前所測效果是相對好的;接著針對 4 Whisper-Finetune 裡提到的加速預測,會因為少了這兩個 preprocessor_config.json 和 tokenizer.json 而導致 large-v3 無法轉換,解法就是如下面兩個 issue 所列,你可以去找到有這兩個檔案的 v3 模型,然後放進去就可以轉換了 !






https://github.com/flutydeer/audio-slicer
Ultimate Vocal Remover 5 (UVR5) 是一款基於深度神經網路的樂器分離軟體。 它透過訓練模型,能夠準確地將鼓、貝斯、人聲等其他聲部分開。
https://github.com/Anjok07/ultimatevocalremovergui
https://ultimatevocalremover.com/
到這邊差不多確定要怎樣做,就是要開始製做數據了,印像中記得要做你自己的ASR場景微調,至少要 100 小時,所以特地寫了個小工具,可以用來改ASR的錯字

最後就是針對ASR辨識後的修正了,目前看來客服語音應該是不太能這樣直接套用;這部份的實驗就暫時也不介紹了,畢竟這篇是先針對 ASR 在實際可能的商業場景落地會踩到的坑 ?
https://github.com/microsoft/NeuralSpeech/tree/master/FastCorrect
https://github.com/microsoft/NeuralSpeech/tree/master/FastCorrect2
https://github.com/microsoft/NeuralSpeech/tree/master/AdapterASR
https://github.com/shibing624/pycorrector/blob/master/README.md
糾錯其實也會需要數據,包括了音似和形似,所以也得再自己寫個工具來製作數據;這個就要看你有沒有逐字稿了 ! 這邊也想給自己做個筆記,在 whisper 問世前,較常聽到的兩個 ASR 訓練調校工具就是 wenet 和 espnet;語料方面強列建議要注意品質,不要以為這是找幾個實習生或者工讀生就能搞定的,特別是深度學習,你的數據花了多少時間下去準備,就能讓你的模型獲得多少時間的效果;通常要針對一個語言模型,那就是至少要先準備100小時,如果是從零開始做到商用,印像中記得 3000 小時是跑不掉的。


中文語音合成 Chinese Speech Synthesis
- https://github.com/fishaudio/fish-speech
- https://github.com/index-tts/index-tts
- https://github.com/canopyai/Orpheus-TTS
- https://chattts.com/zh
- https://github.com/RVC-Boss/GPT-SoVITS
- Seed-TTS
- https://github.com/myshell-ai/MeloTTS
- https://github.com/fishaudio/Bert-VITS2
2025/03 更新:https://github.com/fishaudio/fish-speech
目前個人比較偏向使用這個,速度快,算蠻像 ! 另外原因就是考量自己佈署還得 GPU 的費用啊。
2025/03 更新:https://github.com/index-tts/index-tts
https://huggingface.co/spaces/IndexTeam/IndexTTS
破音字不行,中文語音有點不太像,有DEMO 可以自己體驗一下效果
2025/03 更新:https://github.com/canopyai/Orpheus-TTS
https://huggingface.co/spaces/MohamedRashad/Orpheus-TTS
有DEMO,但測試尚無法生成中文語音?
但是另外發現了這個
Generate lifelike audio in real-time without a GPU!
https://github.com/freddyaboulton/orpheus-cpp
2024/08 補充更新:https://chattts.com/zh
https://github.com/RVC-Boss/GPT-SoVITS/
GPT-SoVits: 上線兩天獲得了1.4k star的開源聲音克隆項目,1分鐘語音訓練TTS模型
DeepLearning101/GPT-SoVITS_TWMAN
GPT-SoVITS是由GitHub暱稱為RVC-Boss的RVC變聲器的創始人與AI音色轉換技術專家Rcell合作開發的一個開源專案。它是一個跨語言音色克隆工具,專注於聲音的轉換和克隆;Bert-VITS2是由fishaudio發起基於VITS (Variational Inference for Text-to-Speech)開源項目模型進行開發,提供高品質的文字轉語音 (TTS)。實現了文字轉語音的語音合成,還無法實現SVC (歌聲轉換)、SVS (歌聲合成) 等唱歌功能。目前測過,GPT-SoVITS產出的效果是較好的 (僅需約1-2分鐘便有讓人滿意的效果),所以就先針對它做介紹吧;官方有自帶 colab 給你玩就是。
https://github.com/RVC-Boss/GPT-SoVITS/blob/main/colab_webui.ipynb
網路上也找到一篇蠻詳細的介紹:GPT-SoVITS帶你體驗AI聲音克隆的魔力






2025/03 更新:Seed-TTS







1. 解決 Eigen3 缺失問題
Eigen 是一個高階 C++ 函式庫,用於處理線性代數、矩陣和向量運算。 若你的系統中未安裝 Eigen,你需要安裝它。 在 Ubuntu 或類似 Debian 的系統中,你可以透過以下命令安裝:
sudo apt-get update sudo apt-get install libeigen3-dev
這會安裝 Eigen 並通常將其頭檔放在 /usr/include/eigen3 目錄下。
2. 解決 Boost 函式庫問題
Boost 是一個廣泛使用的 C++ 函式庫,你的專案可能依賴其多個模組(如 program_options、system、thread、unit_test_framework)。 若這些模組未找到,你需要確保已安裝對應的 Boost 函式庫。在 Ubuntu 或類似 Debian 的系統中,安裝 Boost 程式庫及其開發檔案通常如下:
sudo apt-get update sudo apt-get install libboost-all-dev
如果你需要特定版本的 Boost 或特定元件,你可以透過套件管理器搜尋對應的套件名稱,例如:apt-cache search libboost 然後安裝需要的組件。
確保你的 CMakeLists.txt 檔案中配置了正確的路徑來尋找這些依賴。 對於 Eigen3,你可能需要在 CMake 設定中設定 Eigen3_DIR,例如:set(Eigen3_DIR "/usr/include/eigen3")
或更準確地使用 find_package 方法指定所需的元件和版本號。重新運行 CMake
解決了依賴問題後,回到你的專案目錄並重新執行 cmake 指令:
cd /opt/data/twm-correct/kenlm/build cmake ..
這應該解決了先前的配置錯誤