2023/08 公司添購 RTX 6000 Ada 48 GB * 2 和 A 100 80GB * 4
2024/05 公司添購RTX 6000 Ada 48 GB * 8 * 2
基於機器閱讀理解(MRC)的指令微調(Instruction-tuning)的統一信息抽取框架之診斷書醫囑擷取分析
https://github.com/Deep-Learning-101/Natural-Language-Processing-Paper/#hugnlp
Development Process Record for Diagnosis Document Prescription Text Analysis: Five Algorithms Comparison.
In the pursuit of analyzing diagnosis documents and prescription texts, we experimented with five different algorithms in the following order: UIE from PaddleNLP, ChatGPT 3.5, UniIE, InstructUIE, and HugIE. We welcome in-depth discussions on algorithms, models, data, and related techniques!
HugIE: A Unified Chinese Information Extraction Framework via Extractive Instruction Prompting

金融科技 (FinTech)一直很常在新聞版面看到,但過去實在沒機會參與到;而一直以來除了努力做出高大上的學術研究論文,更期待自己可以將相關演算法落地到實際場景。剛好最近半年,因緣(想)巧(不)合(開),意外(斜槓)到金融業參與了金融科技,並將AI落地到人壽/產險等保險科技的場景 (後續會再分享光學文字識別、語音識別、聲紋識別等過程),希望透過AI來協助傳統登打人員及其核保的工作效率;所以記錄一下整個血淚史 ! 雖然這中間也是一堆像是沒人力 (自幹)、沒硬體 (自購)、沒數據 (自標) 等等三自 (不是三立跟自由哦) 的無言困擾;讓我百思不得其解,不是說 AI 多夯 ? 大家都在/想做 AI嗎 ? 怎好像不是這樣?好,廢話不多說,來看看上半年的第一個工作細節,還有未來要注意那裡;上工 ! 整個想要處理的是診斷書,先透過光學文字識別(OCR),得到相關資料後,再進一步針對診斷書其醫囑文字做分析;那就再來看看要對醫囑(範例)產出怎樣的結果,首先,就是要從醫囑中分析出以下各個字詞跟其關係。
- (A) 住院: 起始日, 終止日, 天數
- (B) 燒燙傷: 起始日, 終止日
- (C) 加護病房: 起始日, 終止日
- (D) 門診: 起訖日, 次數
- (F) 手術: 起訖日, 項目, 次數
- (G) 急診: 起始日, 終止日, 起始時間, 終止時間
- (H) 癌症化療: 起始日, 終止日, 次數
- (I) 罹癌: 起始日, 終止日
- (J) 癌症放射線: 次數, 起始日, 終止日
如果這是一條醫囑:" 患者因上述原因於民國112年5月10日來院接受子宮腔鏡瘜肉切除手術依病歷記錄患者接受醫師於2023-05-02、2023-05-09,醫師於2023-05-16、2023-05-19之本院門診追蹤治療共計4次。" 那其結果應該要跟據前述字詞分析出像這樣的結果:
- 門診起始日:1120502
- 門診終止日:1120502
- 門診起始日:1120509
- 門診終止日:1120509
- 門診起始日:1120510
- 門診終止日:1120510
- 門診起始日:1120516
- 門診終止日:1120516
- 門診起始日:1120519
- 門診終止日:1120519
- 手術起始日:1120510
- 手術終止日:1120510
- 手術名稱:子宮腔鏡瘜肉切除手術
從上面這個範例,可以發現即使只提到門診日期,且門診通常是單一天結束,你不只要能識別出有門診這個項目,還需要能自主識別分析出起始日和終止日皆是同日的結果;同理,手術也一樣,並且要抓出手術名稱。
再來一條醫囑範例:"病人因上述疾病,於民國112年04月05日入住本院-般病房,於民國112年04月06日接受脊髓鞘內射化學藥物治療)於民國112年04月07日至民國112年05月07日接受自費百利妥射劑靜脈津特化學治療,於民國112年05月09日出院,出院後宜休春並持續追蹤治療。"
- 住院起始日:1120405
- 住院終止日:1120509
- 癌症化療起始日:1120406
- 癌症化療終止日:1120406
- 癌症化療起始日:1120407
- 癌症化療終止日:1120407
- 癌症化療起始日:1120507
- 癌症化療終止日:1120507
再來一則超難的案例:病人因上述原因,於民國112年02月09日18時39分至本院急診就診,於同日19時53分轉本院燒燙傷加護病房住院,於民國112年02月16日、02月20日、02月23日、03月02日接受清創手術,因病情穩定,於民國112年03月03日轉至燒燙傷一般病房,於民國112年03月09日接受清創手術,於民國112年03月31日從燒燙傷一般病房出院,建議穿戴彈性壓力衣,宜於門診持續追蹤治療。
- 住院起始日:1120209
- 住院終止日:1120331
- 燒燙傷病房起始日:1120209
- 燒燙傷病房終止日:1120331
- 加護病房起始日:1120209
- 加護病房終止日:1120303
- 手術起始日:1120216
- 手術終止日:1120216
- 手術名稱:左手雙下肢及會陰部二度燙傷清創手術
- 手術起始日:1120220
- 手術終止日:1120220
- 手術名稱:左手雙下肢及會陰部二度燙傷清創手術
- 手術起始日:1120223
- 手術終止日:1120223
- 手術名稱:左手雙下肢及會陰部二度燙傷清創手術
- 手術起始日:1120302
- 手術終止日:1120302
- 手術名稱:左手雙下肢及會陰部二度燙傷清創手術
- 手術起始日:1120309
- 手術終止日:1120309
- 手術名稱:左手雙下肢及會陰部二度燙傷清創手術
- 急診起始日:1120209
- 急診終止衵:1120209
- 急診起始時間:183900
- 急診終止時間:195300
看其結果就知道住院也是同樣的道理 ! 看懂嗎 ? 很簡單嗎 ? 不,一點都不簡單 ! 基本上這並不能算是 命名實體識別(NER),勉強能算是巢狀式命名實體識別、事件擷取 (Event Extraction) 或者 資訊抽取 (Information Extraction)。但不彷先看看以下維基百科的介紹,應該能理解這真的不是上述那幾種吧 ?
資訊抽取主要是從大量文字資料中自動抽取特定訊息,以作為資料庫存取之用的技術。 資訊抽取的一個廣泛目標是允許對以往非結構化的資料去做計算,具體來說就是要允許邏輯推理能對輸入資料的邏輯內容可以舉一反三。其意義在於決定了例如在網際網路上其非結構化形式中有用資訊數量的成長。
事件抽取是信息抽取研究中一項重要且具有挑戰性的任務,在信息檢索、智能問答和知識圖譜構建等方面有著廣泛的實際應用。事件是指某件具體事情的發生,描述事件的信息包括;事件發生的時間和地點、事件的內容和狀態、事件的一個或多個參與者等。事件抽取任務旨在將此類事件描述信息從非結構化純文本中提取為結構化形式。
命名實體識別,又稱作專名識別、命名實體,是指識別文本中具有特定意義的實體,主要包括人名、地名、機構名、專有名詞等,以及時間、數量、貨幣、比例數值等文字。指的是可以用專有名詞標識的事物,一個命名實體一般代表唯一一個具體事物個體,包括人名、地名等。
==============我是分隔線==============
陸續分別嘗試了五種,依序是 PaddleNLP的UIE、ChatGPT 3.5、UniIE、InstructUIE、HugIE;依續做一下相關的介紹;但做深度學習,不能夠忽略的就是數據標註,也是大家通常都不喜歡做的。
標註工具
話雖如此,一開始還是傻傻的用NER再加關係抽取的方式來標註,很快就發現根本標不出來
When it comes to deep learning, data annotation is a crucial step that is often disliked by many. Initially, we tried using Named Entity Recognition (NER) combined with relation extraction to annotate the data. However, we quickly realized that this approach was inadequate and couldn't produce the desired results.

於是換了個方式,改用所謂的事件擷取來標註

發現仍舊無法很順利的標註出想要的效果,傷腦筋很久

PaddleNLP的UIE
PaddleNLP實戰——信息抽取(InfoExtraction)

修正了好多次後,勉強訓練了一個版本,效果如下DEMO看起來還堪用,可惜準確度仍舊未能到85%左右

ChatGPT 3.5
當然啦,LLM 模型正夯,大家都在那邊 GPT,怎能不試試看呢 ? 雖然大家壓根沒搞清楚這到底是怎回事 !
Of course, with the popularity of large language models (LLMs), it was essential to give ChatGPT a try. Although it's unclear how it works, it appears to be quite impressive!

效果看起來也真的是很勵害,只要你 prompt 下得準,它真的可以很精準的給你想要的

即使直接用 API 來做,整體的流程和效果也是很棒,BUT 就是這個 BUT,很多資料其實都會卡在個資法,你不能隨便把這些資料往雲端送 ! 所以,這還是沒局 !
EHR_NER (與用閱讀理解的想法雷同)
Nested Named Entity Recognition for Chinese Electronic Health Records with QA-based Sequence Labeling
後來,Google到這篇論文跟github,復現過程也不算太難,大概看了一下,其原理跟所謂的機器閱讀理解蠻接近,作者自己設計出了一種數據的標註方式,可是,仍舊無法滿足咱家BU端的神奇要求 !

UIE (中斷)
https://zhuanlan.zhihu.com/p/589054073


UniIE (中斷)
後來又找到了這兩個跟大語言模型觀念蠻接進的,但數據標註又是整個不同的方法了
Later, we found these two approaches that align quite well with the concept of large language models. However, their data annotation methods differ significantly.
InstructUIE (中斷)
大模型時代信息抽取任務該何去何從?復旦發布InstructUIE提升大模型信息抽取能力
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction https://arxiv.org/abs/2304.08085
HugNLP:測試迭代更新中
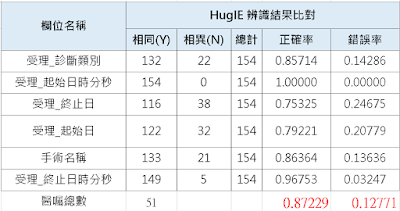
最後,這一切可謂皇天不負苦心人啊,好險平常就有習慣定時在追蹤整個深度學習 (Deep Learning) 的各種演算法的新論文跟新工具,就這樣被我發現這個用 Transformer 做的新框架工具,在完全還沒做任何訓練還有數據標註的情況下,對整個 code 略修整,就得到這驚人的結果 !
Finally, all our efforts paid off when, fortunately, I regularly kept track of new research papers and tools in the field of deep learning. I stumbled upon this new framework, built with Transformers, and without any training or data annotation, after a minor code adjustment, we obtained astounding results!

